Introduction
LLMs (Large Language Models) have revolutionized NLP (Natural Language Processing) and are still transforming the field and its applications as of 2025. These models excel at common NLP tasks such as summarization, question answering, and text generation. A common trend in state-of-the-art LLMs is that they base their architecture on the Transformer’s architecture 1 , and decoder-only models have gained favorability compared to encoder-only or encoder-decoder models 2 . In this article, I will discuss how to use the BERT (Bidirectional Encoder Representations from Transformers) model 3 for a sequence classification task with the Huggingface’s transformers library. Remember that BERT is technically just a language model due to its relatively small sizes (~ 100 to ~350 million, depending on the version) compared to large language models with billions of parameters, and it is an encoder-only model. Nevertheless, as I will argue next, understanding and knowing how to use this model is essential.
So, why should we still care about BERT in 2025? First, it has historical significance as one of the first models to showcase the power of the Transformer architecture, and anyone working with LLMs should be familiar with it. Second, smaller, encoder-only models such as BERT are better suited for powerful interpretability and explainability techniques, including LIME 4, SHAP 5, and attention visualization using tools such as BERTViz 6,7 , or exBERT 8 . Third, BERT models excel at tasks such as sequence classification, i.e., intent classification or sentiment analysis, and name entity recognition, and for specific applications, it is a better option than modern LLMs. Fourth, BERT models are more cost-efficient, require fewer computing resources, are more environment-friendly, and can be more easily deployed for large-scale applications than LLMs. Finally, if you learn how to use BERT with the transformers library, you can apply the same skills to other state-of-the-art open-source LLMs.
Huggingface’s transformers library
Huggingface’s transformers is a wonderful open-source library that empowers users to use pre-trained models for multiple tasks in modalities such as Natural Language Processing, Computer Vision, Audio, and Multimodal. One of its core advantages is its support and interoperability between various frameworks such as PyTorch, TensorFlow, and JAX. 9 . You can find a list of the models supported here Supported models and frameworks, and comprehensive documentation for BERT 10
Model checkpoints and architectures
Using BERT requires choosing an architecture and a checkpoint. A checkpoint indicates the state of a pre-trained model, such as its weights and configuration. These are some examples of widely used BERT checkpoints.
| Checkpoint (model-card) | Notes |
|---|---|
| bert-base-uncased | Trained on lowercased English text |
| bert-large-uncased | Larger version of bert-base-uncased |
| bert-base-cased | Account for capitalization |
| bert-large-cased | Larger version of bert-base-case |
| bert-base-multilingual-uncased-sentiment | Finetuned for sentiment analysis |
| bert-base-ner | Fine-tuned for Named Entity Recognition (NER) |
The choice of architecture depends on the task that you are planning to do. These are some of the main architetures used with BERT.
| Task | Architecture |
|---|---|
| Sequence Classification | BertForSequenceClassification |
| Token Classification | BertForTokenClassification |
| Fill Mask | BertForMaskedLM |
| Question Answering | BertForQuestionAnswering |
| Multiple choice | BertForMultipleChoice |
Using a pretrained BERT model for sequence classification
Pipeline overview
The three stages for sequence classification with BERT are as follows: stage 1: preprocessing, where we convert the utterance into tensors using the tokenizer. Next, in stage 2, we use these tensors as inputs for the model, and the model outputs logits. Finally, these logits are converted into probabilities using the Softmax function.

Figure 1 illustrated these three stages at a high-level. We will implement each stage and discuss the results in later sections.
Complete source code
To efficiently run this code, please check sequence_classification.ipynb or sequence_classification.py. If you want to run it on your machine, install the transformers and torch packages.
For a detailed guide on how to install packages on a Conda environment, please check this article: Setting up a Conda environment.
Show Code
| |
Instantiate model and tokenizer
Note: Complete source code is included here complete code
Downloading and storing the model and tokenizer
How do we download a Hugginface’s model and its respective tokenizer? We only need a checkpoint and its respective architecture, as mentioned in here. For this post, we will be using the checkpoint nlptown/bert-base-multilingual-uncased-sentiment to do sentiment analysis for product review, and the BertForSequenceClassification architecture. Remember that we use the AutoTokenizer class to download the correct tokenizer automatically using the checkpoint. If you run the code, you will see that the tokenizer is a BertTokenizerFast object with a vocabulary size of 105,879.
| |

If you run the above script, you will see in
Figure 2
that the model and tokenizer files are stored in a model directory. The config.json has the core information, such as model name, architecture, and output details. Also, the model weights are stored in the model.safetensor. Please review these files to understand the model we will use better.
config.json
| |
Stage 1: Tokenize input
Note: Complete source code is included here complete code
Transformer-based models such as BERT cannot process raw utterances. We first need to use the tokenizer to convert a string into multiple tensors, which will be the actual inputs to the model as illustrated in
Figure 1
. These tensors are inputs_ids, token_type_ids, and the attention_mask.
inputs_ids: Represents each token with an id based on the model’s vocabulary.token_type_ids: Indicates which tokens should be attended to or ignored using 1 or 0, respectively.attention_mask: Distinguishes segments in an input, where each integer belongs to one specific segment. For inputs with one segment, all values will be 0.
| |
This is the output when using the positive review: "I really loved that movie". Please note the token_id to token mapping at the end. This shows how the tokenizer splitted the utterance into tokens, and converted that token into a token id. Also note that {'101': '[CLS]'}, and {'102': '[SEP]'} are special tokens, corresponding to the classification, and separation tokens, respectively.
output
| |
Stage 2: Model inference
Note: Complete source code is included here complete code
Model inference is the stage where we use the model weights to get a result. In this case, we want to predict the rating (star (s) from 1 to 5) based on a user utterance.
| |
output
| |
Stage 3: Post process results
Note: Complete source code is included here complete code
The raw output of the model in stage 2 is called logits. We need to apply the softmax fuction to get the probability distribution over the 5 stars ratings. Softmax in the context of PyTorch is defined as
$$ \begin{equation} Softmax(x_i) = \frac{exp(x_i)}{\sum_j exp(x_j)} \label{softmax} \end{equation} $$Where Softmax \eqref{softmax} is applied to all the slices along dim, in our case, dim=-1 (5) since we have 5 stars (1 -> 5).
| |
output
| |
Examples
Output: Positive review
Complete pipeline’s output when using a positive review such as “I really loved that movie”.
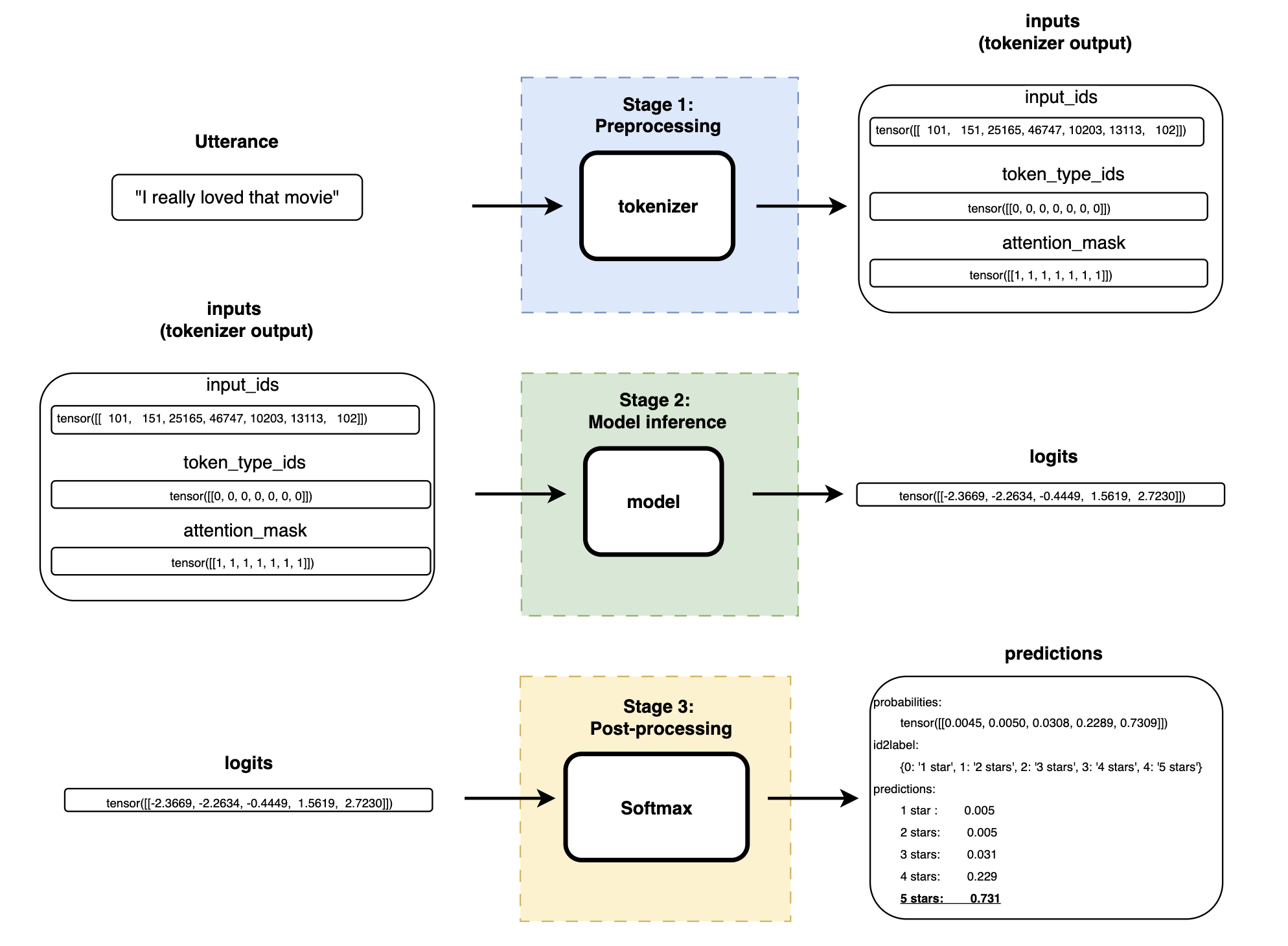
| |
Output: Negative review
Complete pipeline’s output when using a positive review such as “I really loved that movie”.
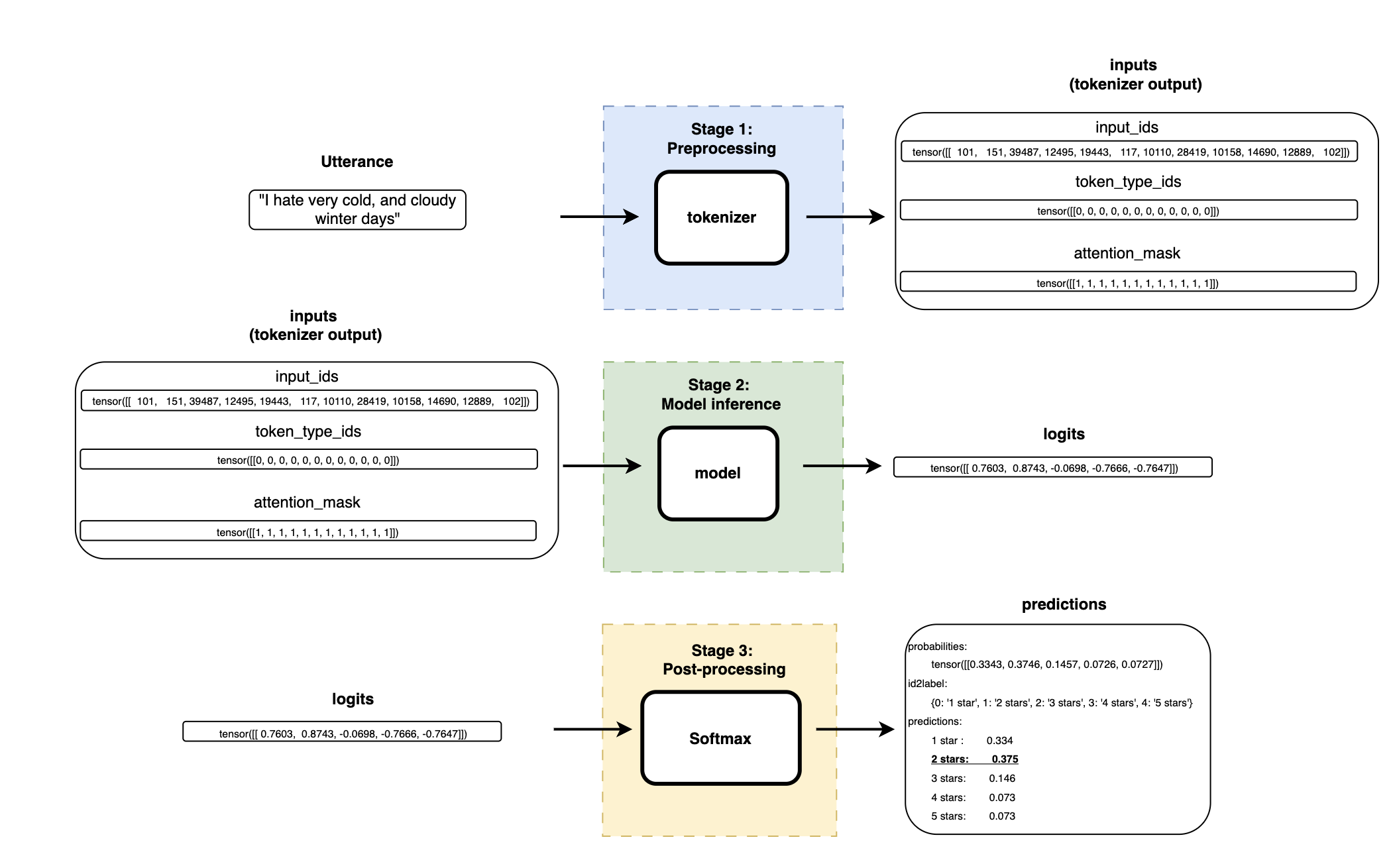
| |
Conclusion
You now have all the tools to use BERT for sequence classification. Please check the vast number of checkpoints and architectures you could use for various applications. You can see some of the most common ones here. Furthermore, if you want to better understand this material, one great way to do it is to run the scripts provided with a debugger and see the results yourself. Finally, remember that you can apply these skills to download and start using some of the state-of-the-art LLM models listed here.
References
A. Vaswani et al., “Attention Is All You Need,” Aug. 01, 2023, arXiv: arXiv:1706.03762. Accessed: Apr. 03, 2024. [Online]. Available: http://arxiv.org/abs/1706.03762 ↩︎
J. Yang et al., “Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond,” Apr. 27, 2023, arXiv: arXiv:2304.13712. doi: 10.48550/arXiv.2304.13712. ↩︎
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds., Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4171–4186. doi: 10.18653/v1/N19-1423. ↩︎
M. T. Ribeiro, S. Singh, and C. Guestrin, “‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier,” Aug. 09, 2016, arXiv: arXiv:1602.04938. doi: 10.48550/arXiv.1602.04938. ↩︎
S. Lundberg and S.-I. Lee, “A Unified Approach to Interpreting Model Predictions,” Nov. 25, 2017, arXiv: arXiv:1705.07874. doi: 10.48550/arXiv.1705.07874. ↩︎
J. Vig, “A multiscale visualization of attention in the transformer model,” in Proceedings of the 57th annual meeting of the association for computational linguistics: System demonstrations, M. R. Costa-jussà and E. Alfonseca, Eds., Florence, Italy: Association for Computational Linguistics, Jul. 2019, pp. 37–42. doi: 10.18653/v1/P19-3007. ↩︎
J. Vig, jessevig/bertviz. (Mar. 02, 2025). Python. Accessed: Mar. 02, 2025. [Online]. Available: https://github.com/jessevig/bertviz ↩︎
B. Hoover, bhoov/exbert. (Mar. 02, 2025). Python. Accessed: Mar. 02, 2025. [Online]. Available: https://github.com/bhoov/exbert ↩︎
“🤗 Transformers.” Accessed: Mar. 03, 2025. [Online]. Available: https://huggingface.co/docs/transformers/index ↩︎
“BERT.” Accessed: Mar. 03, 2025. [Online]. Available: https://huggingface.co/docs/transformers/model_doc/bert ↩︎