🔋Pilas: y25-w34
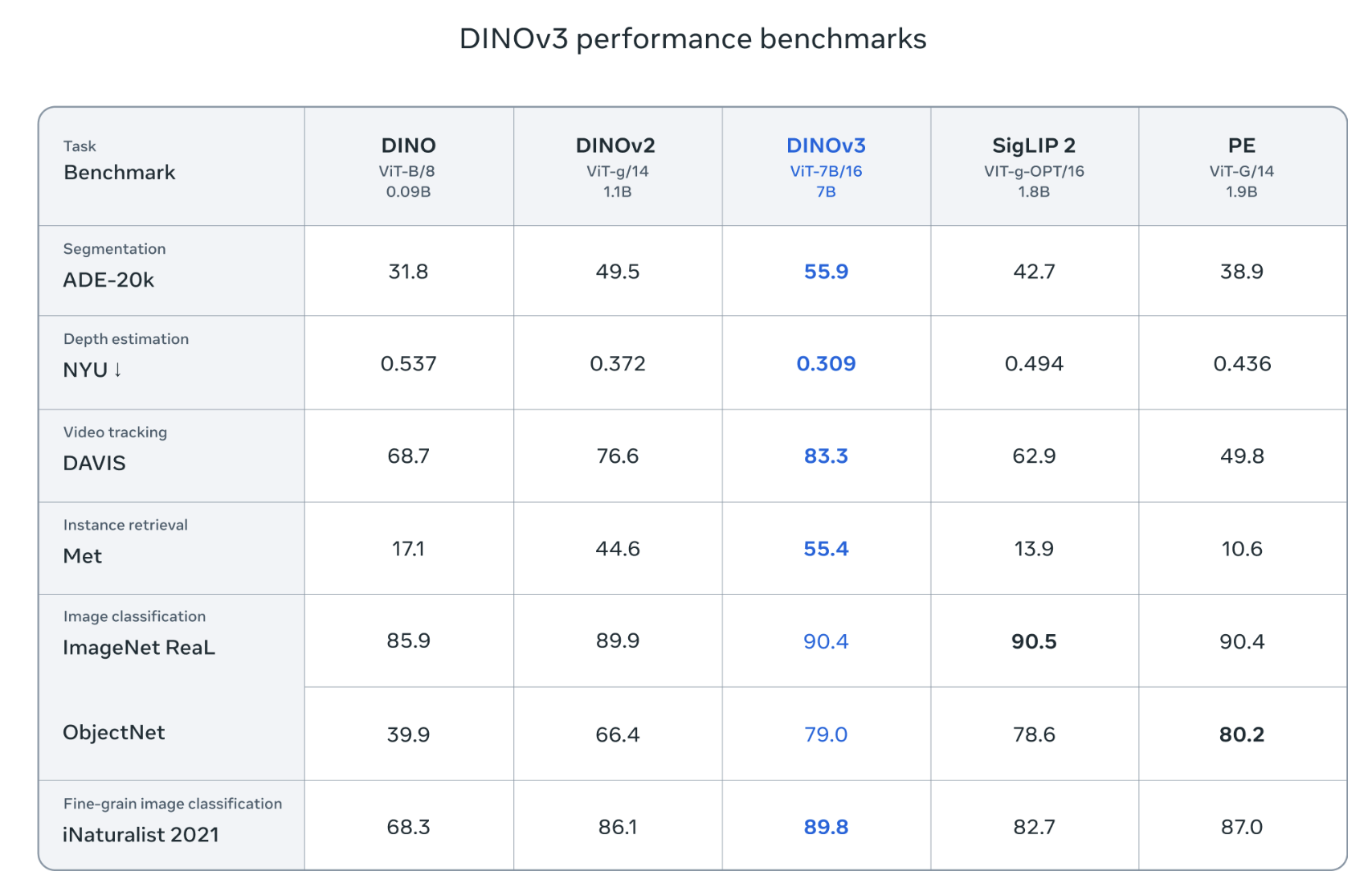
Releases DINOv3 Paper: Hugging Face Arxiv Huggin Face Collection Blog post: DINOv3: Self-supervised learning for vision at unprecedented scale Website: Self-supervised learning for vision at unprecedented scale DINOv3 is a generalist, computer vision foundation model that scales self-supervised learning (SSL) and produces high-resolution visual features eliminating the need for labeled data. Figure 1: DINOv3 benchmarks Intern-S1: A Scientific Multimodal Foundation Model Paper: Hugging Face – Arxiv Models: Intern-S1 – Intern-S1-mini Intern-S1 is a large-scale multimodal Mixture-of-Experts (MoE) foundation model released by The Shanghai AI Laboratory. It is designed to close the gap between general-purpose open-source models and expert-level closed-source models in scientific domains. The model has 28 billion active parameters, 241 billion total parameters, and it was pretrained on 5T tokens. The authors used Mixture-of-Rewards (MoR), a novel RL technique to train simultaneously on more than 1000 tasks. ...